Architectural Notes
- Why are things the way they are?
- The Cluster View
- Global Clock
- Playbooks
- Scheduling Node Actions
- Cluster discovery
- Cluster orchestration
- Handling data models
- Distributed Coordination
- Scaling
- Releasing
Premature Optimisations
- Should it be better?
- Concurrent Agent Fetches
- Dynamic Config
- Rewrite Kafka Consumer
- Online Kafka stream resize
- Layered Configuration
- Lock validation before writes
- Multi-cache backend
- Stream Batches
- Rewrite Zookeeper Elections
- Path-based Apply API handlers
Dreamland
- What could the future bring?
- Auditing System
- Best practices checklists
- Cluster Groups
- Cluster Tags
- Replicante Core bootstrapping procedure
- Failure triggers detection
- Generic backends interface
- Metrics based insight
- Multi-Cluster Playbooks
- Multiple agent transports
- Node events collection
- Playbook Variables
- Provisioning integrations
- Rate Limits
- Read only mode
- Replication window metrics and re-sync times
- Resyncable WebUI application
- Secrets manager integrations
- TLS certificate rotation
Cluster discovery
The cluster discovery process aims to keep administration and management overheads at a minimum and take advantage of the highly dynamic platforms and tools available today (“The Cloud”).
So how does cluster discovery work?
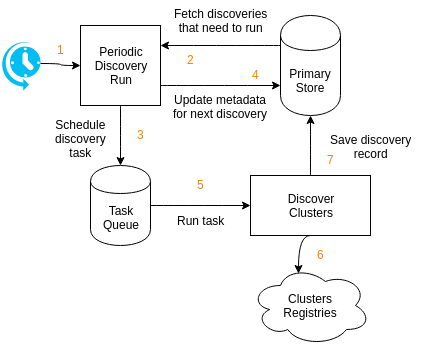
- Users apply one or more
DiscoverySettingobjects though the API. - The cluster
discoverycomponent periodically runs at fixed intervals. The interval should be short as it determines the delay between discoveries needing to run and them being scheduled. - The
discoveryrun looks for any discoveries with an expected next schedule time in the past. If no cluster discovery needs to run thediscoveryrun does nothing. - The
discoveryrun schedules a discovery task for each discovery that needs to be performed. - The expected next schedule time is updated to
now() + discovery interval. - A task worker picks up the discovery task.
- The discovery task fetches discovery records from the given discovery.
- Discovery records are updated in the primary store.
Deleting clusters and nodes
When clusters and nodes are automatically discovered they can also automatically go away.
This feature is not currently available and is yet to be designed in full.
Why discover clusters?
The primary use case for Replicante is part of an automated, distributed, dynamic infrastructure that scales from a small number of small clusters to a large number of large clusters.
It is assumed that managing a list of nodes is at best impractical, but may even be impossible in combination with tools such as auto scaling groups and automated instance provisioners.
The idea of cluster discovery was inspired by Prometheus. Cluster discovery has several advantages:
- A single source of truth as to which instances should exist in which clusters.
- Automatic detection of node creation and retirement.
- Nodes are “checked” against some form of trusted server inventory (nodes can’t just add themselves to a cluster).